Contents

9 Strong Tips to Prevent Web Scraping in 2025
Imagine this situation: Instead of spending your weekend at the beach, you’re creating valuable content for your website. (It can be pricing, product info, blog posts, or some important insider information.)
And then the next weekend, while you’re finally relaxing on the beach, soaking up the sun, a sneaky bot slips into your website, grabs all of your content, and runs off like a digital thief.
Pretty rude, right?
That’s why you need to know how to prevent website scraping, so your content stays safe.
In this blog, we’ll show you 9 ways to stop website scraping, and we’ve added a bonus tip at the end that’s a game-changer.
So let’s get into it and keep your site safe!
But first,
Why Do You Need Web Scraping Protection?
1. To protect Your Content
Imagine you worked hard to create your content, whether it’s product info, prices, blog posts, or reviews.
And suddenly, someone steals all your content and reposts it somewhere else. How frustrating isn’t it?
Scrapers can do this.
And that can:
- Hurt your rankings on Google
- It makes your brand look less trustworthy
- Or it leads to people copying your stuff without permission
2. To Stop Your Competitors From Spying
Your competitors and other companies use scrapers to keep an eye on your pricing, product updates, or anything else you post on your website.
(Basically to copy your moves.)
That’s why good scraping protection keeps your business secrets… well, secret.
3. To Keep Your Website Running Smoothly
A web scraping bot can harm your website by sending nonstop requests.
A scraping bot can:
- Slow down everything
- Increase your server costs
- In some cases, even crash your site
By blocking them, you can give a fast and smooth experience to the real visitors.
4. To Catch Bigger Problems Early
Scraping is not always harmless. Sometimes, it’s a setup for something worse, like trying to hack into accounts or undercut your pricing strategy.
By stopping scrapers early, you are not just protecting your content, you are staying one step ahead of bigger threats.
5. Follow The Rules
There are some pretty strict laws, like GDPR and CCPA, for how personal data is collected and used.
But some web scraper bot might grab private information from your site that you are not even allowed to share.
Using techniques to prevent website scraping tells that you are playing by the rules, and it helps keep you out of legal trouble.
How to Prevent Web Scraping?
1. Use CAPTCHA and JavaScript Challenges
Alright, when it comes to protecting sites from scrapers and bots, CAPTCHAs and JavaScript challenges are like the front-line defense troops.
Although they both are not perfect, they’re still good at stopping bots from scraping websites.
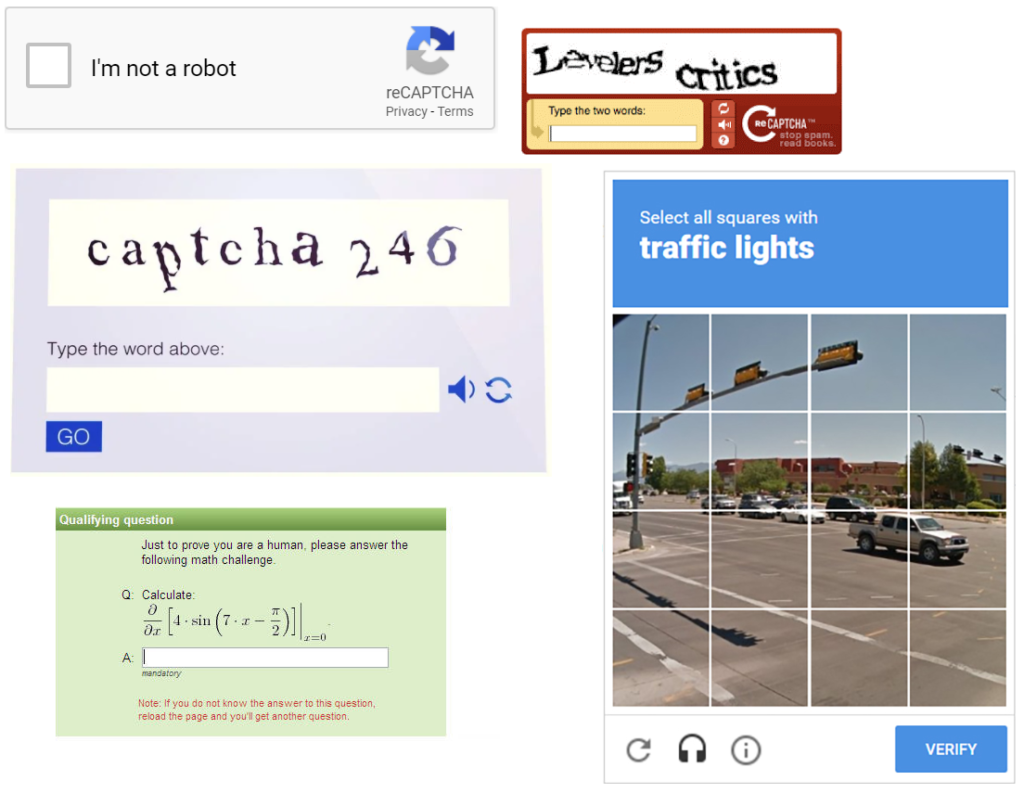
What are CAPTCHAs?

In simple terms = those annoying checkboxes saying “I’m not a robot” or image puzzles asking to find traffic lights, zebra crossings, and bicycles.
Popular options:
- Google reCAPTCHA
- hCaptcha
- Friendly CAPTCHA
Best places to use CAPTCHA:
- Login and registration forms
- Contact or lead capture forms
- Checkout pages
- Pages displaying sensitive or dynamic content
But the real problem is that many advanced bots can still bypass basic CAPTCHAs by using headless browsers or automation tools.
That’s where JavaScript challenges come in.
Why add JavaScript challenges?
Because many still struggle to fully execute JavaScript.
You can throw in tricks like:
- Delaying how your content loads
- Using dynamic tokens or cookies
- Adding hidden fields that only real browsers can handle
- Tracking simple user behavior, like mouse movements or scrolling
These kinds of checks trip up bots because they can’t always handle full JavaScript execution or act like real users.
Pro tip: Use both.
CAPTCHA might stop simple bots,
JavaScript can slow down or block more advanced scrapers.
2. Rate Limiting & Throttling
Not all scrapers can go full ninja mode.
Some scrapers bombard your site by sending too many requests at lightning speed.
That’s where rate limiting & throttling help.
What is rate limiting?
Rate limiting controls how many requests a single IP address or user agent can make in a certain time frame.
If a user goes beyond that limit, their access gets blocked or delayed.
It’s very simple, effective, and great for finding any suspicious activity.
Example: If a website has a limit of 100 requests per IP per hour, and one user sends more than 100 requests, their access will get blocked.
What is throttling?
Rate limiting = blocks excess traffic
Throttling = slows it down
In simple terms, instead of cutting off access completely, you can delay response or queue them.
Key use cases:
- To identify and block burst traffic
- To avoid API abuse
- To manage scraper overload
- To safeguard server resources
Tools you can use:


3. Block Suspicious User Agents
Every time someone or something visits your website, they introduce themselves with a special name tag saying:
“Hi, I’m Chrome” or “I’m Safari on an IPhone.”
This name tag is called a user agent.
Means it tells your website what browsers or tools are being used.
Examples of user agents:
- Mozilla/5.0 (Windows NT 10.0; Win64; x64) Chrome/120.0.0.0
- Safari/537.36
- curl/7.68.0 – suspicious!
- Python-urllib/3.9 – suspicious!
What is a suspicious user agent?
Bots usually visit the website to scrape content or do weird stuff. And many of them don’t even try to hide.
And they use obvious user-agent strings like:
- curl/7.68.0
- Python-urllib
- Scrapy/2.5.1
- Java/1.8.0
That’s a suspicious user agent because it clearly shows that a script is trying to access your site.
Go and block them.
(You can easily block or flag them in your server configuration or through a firewall.)
But,
Why block suspicious user agents?
If you block these “obvious bots,” your website:
- Loads faster for real users
- Is safer from content theft
- Avoids unnecessary server load
But it’s not foolproof…
Smart bots know how to pretend they’re using Chrome or Firefox, so they fake their user agents:
“Hi, I’m Chrome!” (but really it’s a bot)
That’s why blocking user agents is just ONE STEP in your anti-bot strategy.
4. Use Robots.txt
What is robots.txt?
Robots.txt is a simple text file that is placed in your website’s root directory.
It tells web crawlers what they can crawl and what they can’t crawl.
For example,

This tells all bots, “Don’t go into the /folder/ for crawling.”
But the problem is:
Not all bots care about the robots.txt file. Some malicious scrapers often ignore robots.txt completely.

Robots.txt is helpful for guiding good bots like Googlebot, Bingbot, etc, but it’s not a security shield.
Combine it with some stronger protections like rate limiting, JavaScript challenges, and so on, to prevent scraping.
5. Deploy Honeypots to Catch Sneaky Bots
Do you want a quiet way to catch scraping bots without bothering real users?
Then the honeypot is for you.
What are Honeypots?
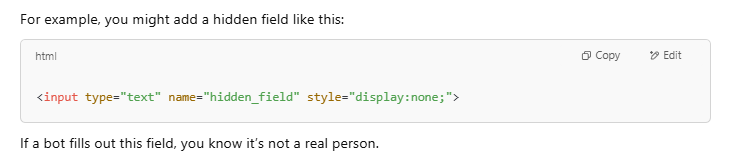
Honeypots are invisible items on your site, such as invisible links or form fields.
Normal users never see or use them.
But bots? They usually interact with everything they find, including the stuff they’re not supposed to.
Why do honeypots work?
Bots usually don’t check what’s visible and what’s not. They just try to grab everything.
So if something invisible gets clicked or filled, it’s a clear sign that you’re dealing with a bot.
What can you do?
If a honeypot gets triggered, you can:
- Block that IP
- Slow down its requests
- Add it to your bot blacklist
Honeypot is a smart way to spot scrapers without disrupting genuine users.
Even though honeypots will not block all the bots but they trap the careless ones.
Combine honeypots with other tools like CAPTCHAs or rate limits for stronger protection.
6. Block Data Centers, VPNs & Proxies
Many web scrapers don’t originate from a normal internet connection like you and me.
Nope, they utilize cloud servers, VPNS, proxies, or even the Tor network to remain anonymous and scrape websites peacefully.
That’s why the intelligent move to cut down bot traffic is to block or monitor IPs from these sources.
Because these provide them with speed, make it simple to rotate IPs, and prevent them from getting blocked.
How to fight back?
Use tools like:
By using these tools, you can identify and block traffic from known data centers, VPNs, and suspicious IP ranges.
Bonus tip: Geo-Blocking
If you only want to serve your website in a specific region (say, just the United States of America), you can limit or block traffic from other regions where you don’t expect real users.
Yeah! It’s not perfect, but it adds another layer.
Remember: Blocking data centers and proxies won’t stop the most advanced bots, but it filters out a lot of noise from basic and medium-level scrapers.
But be sure you’re not blocking genuine users in the process.
7. Monitor & Validate Sessions
Want to make a scraper’s life hard?
Make them act more like real users, with proper logins, sessions, and cookies.
Most bots can’t keep up.
What does that mean?
Rather than allowing everyone access to your content without restrictions, you can:
- Make login or authentication required for valuable content
- Employ session tokens or CSRF tokens
- Verify consistent session behavior (like real users clicking around)
Now bots have to:
- Store and return cookies
- Manage session tokens
- Simulate the way a human would navigate your site
That’s a lot more work, and many scrapers will simply give up.
What to watch for?
Bots typically:
- Skip setting or returning cookies
- Perform strange navigation jumps like loading 10 pages in a second
- Don’t maintain proper session flows
By spotting these indicators, you can easily detect and block them.
In short, genuine users will sign in and follow the rules, but bots won’t do it.
That’s why session validation is a powerful defense against web scraping.
8. Use Dynamic Rendering or Obfuscation
Want to actually mess with bots?
Don’t present everything on a silver platter.
Make them earn it.
What’s the trick?
Most scrapers love static HTML; it’s simple to read and capture.
But if you load important information after the page has loaded (using JavaScript), simple scrapers won’t be able to see it.
Here’s what you can do:
- Load critical content dynamically through JavaScript
- Use signed URLs or time-expiring tokens for data access
- Insert delays or even light encryption into AJAX responses
This forces bots to interpret and execute JavaScript, something most of them aren’t very good at.
Tools & frameworks that assist
Frontend frameworks such as:
- React
- Vue.js
- Angular
…are ideal for this.
They only load content when required, which makes scraping more complicated.
Bonus Tip:
You can even obfuscate or scramble your code, so scrapers can’t easily determine where the data is being obtained from. It’s like hiding the treasure map.
Dynamic rendering doesn’t stop all bots, but it raises the bar significantly.
Instead of handing them a menu, you’re making them cook the meal themselves.
9. Keep an Eye on Logs and Traffic in Real-Time
If a person is scraping your website, your server logs likely have a clue; you just need to check.
What do you look for?
Bots often leave patterns behind.
Here are some red flags:
- Tons of hits to the same pages (such as product pages or prices)
- A big one-day spike in traffic from one IP or IP range
- Predictable, repeated navigation patterns
- Strange or unusual user-agent strings
These don’t always mean scraping, but together? They’re definitely suspicious.
How to catch it?
You can install tools that watch and notify you when something seems unusual.
Some popular choices are:
- ELK Stack (Elasticsearch, Logstash, Kibana)



These tools allow you to monitor real-time activity, create alerts, and even automate a response if necessary.
Consider your logs as CCTV.
Regularly checking them or setting up alerts is one of the best methods of catching scrapers in the act.
Bonus: Use Bot Protection Platforms
Sometimes, calling in the experts is the best defense.
There are many dedicated platforms available that specialize in detecting and stopping bots before they can even touch your valuable data.
Popular bot-fighting tools:


If you use these platforms, then you don’t have to monitor everything manually; these platforms will analyze traffic patterns, detect suspicious behavior, and automatically take action.
Let’s say your site handles some valuable content, pricing data, or customer info, investing in one of these services can save you a lot of headaches (and bandwidth as well).
It’s like hiring a 24/7 security guard for your content.
Use Layers of Protection
To be honest, there’s no magic trick to stop web scraping completely.
Bots are clever, and they’ll keep trying new ways to sneak in.
(It’s true!)
So it’s better to use multiple layers of protection, not just one.
Start with simple protections like:
- Rate limiting
- CAPTCHAs
Then add complexities like:
- Behavior checks
- JavaScript challenges
- Bot protection tools
Each layer will add more difficulty for scrapers.
So when the scrapers find it too hard or too time-consuming to scrape, they’ll just give up.
Why does it work?
If you only use one technique = Scrapers can easily bypass it.
If you use multiple techniques = It becomes much harder for scrapers to scrape a website.
In short:
- No single method is enough to stop scraping
- Mix different tools and techniques
- Update your defenses over time
Don’t Overdo It
I know protecting your site from scraping is important, but don’t go so far that it annoys your real visitors.
Like:
Placing CAPTCHAs on all pages = Irritating experience for users
Blocking too many IPs too quickly = Real users might get locked out
Balancing both is the key. Make it hard for bots, but smooth for real users.
Important thing:
Don’t block the good bots like Googlebot or Bingbot.
They make your website appear in search results.
If you accidentally block them, then your website might disappear from Google.
Final Words
Web scraping is like a never-ending cat & mouse game.
You can’t stop it completely, but you can make your site a tough target.
And every website is different, so your anti web scraping strategy should fit your needs.
Stay flexible, stay alert, and keep evolving.
Related Blog

11 Real-World Use Cases of Web Scraping in 2025
Explore 11 powerful examples of web scraping and see how to use data to gain insights, leads, and a market edge in 2025.

Which Review Scraper Is Best for Your E-commerce Business?
Want a simple way to start scraping reviews? Learn how to grab real customer feedback and make smarter product decisions fast.

How to Scrape Social Media Without Coding (2025 Guide)
Discover how to collect social media data effortlessly with no-code tools in this 2025 guide.