
9 Tips for Scraping Amazon Product Data Safely
Picture this: you wake up early, excited to find the juiciest data from one of the world’s largest marketplaces, Amazon.
You can almost feel the possibilities—discovering trends, spotting game changing opportunities, and gaining that competitive edge.
But then suddenly… nothing but crickets.
Your screen gets flooded with rate limit notifications, and before you know it, your account is blocked. Frustrating, right?
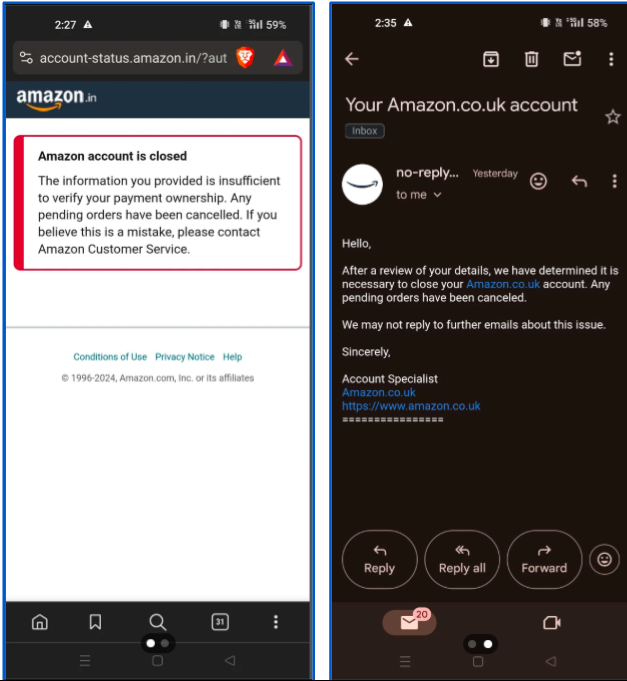
Sounds like you? don’t worry!
Lots of people face this same challenge when they try to get that info the wrong way. But there’s a better, safest, fastest, and most efficient way to lay your hands on those insights without going through this ban challenge like other people do.
What is it? Amazon scraping. It lets you discover golden opportunities off Amazon with just a few moves: point, click, and scrape.
However, you need to use some best scraping practices so you don’t get banned or blocked by Amazon.
So In this post, I’ll break down for you the 9 best practices for Scraping Amazon data without you getting banned. And you’ll learn how to do it safely, ethically, and effectively.
Let’s dive in!
But first, let’s go over what Amazon scraping is.
What is Amazon Scraping
Amazon scraping is a simple process that involves collecting valuable data from Amazon’s massive pool of product information.
For example, if you want to launch an e-commerce store but don’t know which products are trending, you could scrape data like customer reviews, pricing trends, and product availability to make decisions accordingly.
What Can You Scrape?
You can extract over 30+ data points from Amazon, including:
1, Product Names
2, Prices
3, Product Descriptions
4, Seller Ratings
5, Customer Reviews
6, Star Ratings
7, Product Availability
8, ASIN (Amazon Standard Identification Number)
9, Shipping Details… and more!
Why Should You Scrape Amazon Data?
There are over a gazillion reasons you should DEFINITELY scrape Amazon product data but here’s only a few that tops the list:
1. Gives you a competitive edge
For small businesses and individual sellers, Amazon can feel like a battlefield dominated by big players. And so by scraping Amazon data you get to understand the competition, set competitive prices, and position yourself strategically.
This Literally levels out the playing field for you as a seller giving you a competitive edge whether you’re a newbie or a pro.
2. Understanding What Customers Really Want
By analyzing customer reviews, questions, and feedback, scraping digs out the raw, unfiltered voice of the buyer.
This insight goes beyond numbers—it’s about genuinely connecting with customer pain points and delivering products that solve real problems.
PLUS, you get to improve on products with poor reviews or fulfilling unmet needs, so you’re helping create better solutions that positively impact lives.
And that’s a big win for you.
IMPACT = MORE CASH $$$
But hey, you are not Father Christmas to know the exact thing your customers desire.
So if you would like to know exactly what your customers want easily and faster, you can use our free Amazon review scraper to know just that. Great, right?
3. Find Hidden Opportunities
Amazon is huge, and filled with hidden gems and untapped markets—markets that are waiting to be tapped.
And scraping helps you find these opportunities, letting you fill gaps and offer solutions customers didn’t even know they needed (it’s a love potion that will keep them coming again and again lol 😅).
4. Save Time to Focus on What Matters
Time is precious, especially when it comes to growing businesses.
But scraping automates all this complicated process of gathering data so you can focus more on what moves the needle in your business; innovation, customer relationships, and growing your brand with purpose and passion.
HOLY SCRAPE!!!
I must scrape that Amazon data But how on earth do I do it? 😭
Hold up, our Amazon product scraper will help you so worry not!
How to Scrape Amazon Product Data With ScrapeLead Safely And for Free [No-Code]

Scraping Amazon data with ScrapeLead’s Scraper is by far the easiest thing you can ever do on planet earth.
I know I know, actions speak more volumes than words. Soo here’s how you do it in actions in just a simple 4-step process.
- Create a free ScrapeLead account
- Set up the Amazon product scraper
- Copy and Paste the URLs
- Get results in any format you want… CSV, Excel, and JSON
And that’s it.
BUT WAIT!!!
Is Scraping Amazon Data Legal?
Well, it depends on what you are trying to scrape AND whether it aligns with Amazon’s scraping terms of service or not.
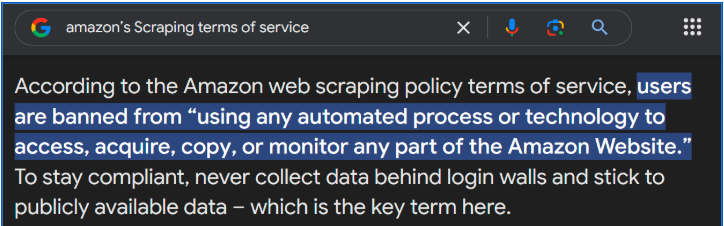
so,
What aligns with Amazon’s TOS? [LEGAL SCRAPING]✅
- Accessing Publicly Available Data
Scraping information that is publicly available on Amazon without bypassing any security measures (e.g., prices, product names, or descriptions). - Respecting Rate Limits
Ensuring that your scraping activity does not overload Amazon’s servers or interfere with its infrastructure complies with ethical and legal boundaries. - Using Amazon’s API
Amazon provides APIs (like the Product Advertising API) specifically for legal data collection. Using these tools ensures your activities are officially approved and stay within Amazon’s guidelines.
What doesn’t align with Amazon’s TOS? [ILLEGAL SCRAPING] ❌
- Bypassing Security Measures
Using tools or methods to dodge Amazon’s security systems (e.g., solving CAPTCHAs automatically or scraping behind login-protected areas). - Overloading Amazon’s Servers
Sending excessive requests at a go that force through Amazon’s servers or disrupt its operations.
- Going after Private or Restricted Data
Trying to access non-public data, such as customer details, hidden stock levels, or proprietary algorithms, is strictly not allowed and can lead to a lot more legal consequences.
But can I get banned? 🥺
Can You Get Banned for Scraping Amazon Data?
The answer is simple and straightforward: YES, you can get banned for scraping Amazon data.
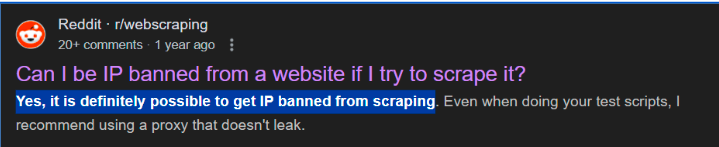
How and why?
HOW: If you scrape data the wrong way.
WHY: Because if you scrape data the wrong way, it doesn’t align with Amazon’s terms of service, meaning? You automatically get on the platform’s little ban–list.
Which is why you need to be strategic and use the best of the safest practices for scraping Amazon data so you don’t get banned.
What are the best practices for scraping data from Amazon without getting banned?
9 Must-Know Practices for Scraping Amazon Data Without Bans
Practice #1: Know Amazon’s Protection Measures
Amazon’s systems are built to detect scraping activity. They use tools like IP tracking, browser fingerprinting, and Captchas to block bots.
So if you don’t know how these systems work, you’ll likely get flagged and banned quickly as counting 1, 2, 3. It’s that simple.
How does Amazon’s system work?
Here’s a quick overview:
| Component | Function |
|---|---|
| Product Listings | Displays products with descriptions, prices, and availability for buyers. |
| Search Algorithm | Matches customer search queries with the most relevant products. |
| Pricing System | Dynamic pricing adjusts based on demand, competition, and other factors. |
| Inventory Management | Tracks stock levels and ensures timely restocking for sellers. |
| Review System | Allows customers to provide feedback, boosting trust and transparency. |
| Buy Box | Highlights the best offer for a product, influencing purchasing decisions. |
| Recommendation Engine | Suggests products based on customer behavior and preferences. |
| Fraud Detection | Identifies and blocks suspicious activities, including scraping attempts. |
That’s more like it.
So how do you work around this system? Easy–understand how Amazon’s detection works so that you can create strategies to stay under the radar, like managing request rates or mimicking natural browsing behavior.
For example:
As a small business you might try to scrape Amazon for product reviews but in the process you don’t account for Amazon’s anti-scraping mechanisms. After an hour? Your IP is banned, slowing down all operations.
SO DON’T ❌
Ignore Amazon’s rate-limiting and Captcha systems. Sending hundreds of requests in a short time will get you blocked in no time.
BUT DO ✅
Learn about Amazon’s detection tools, like IP tracking and Captchas, and configure your scraper to mimic natural browsing behavior with appropriate request limits.
Practice #2: Change Your Internet Connection Often
Scraping multiple pages with the same IP address can raise a red flag, as it’s unlikely for a single user to make so many requests in such a short time.
This makes it pretty much easy for Amazon to quickly spot you out and block such activities.
So if you use this Amazon scrape method, you’re going to have to rotate proxies or use proxy pools to ensure your requests come from different IPs, making your activity appear like it’s coming from multiple users rather than a single bot.
For example:
If you’re a freelancer and scrape Amazon for pricing data using a single IP address. Amazon can identify the repeated activity from the same source and block your IP after 30 minutes or so.
SO DON’T ❌
Use the same IP address for all your requests. This repetitive activity makes it easy for Amazon to flag you.
INSTEAD DO ✅
Use rotating proxies or proxy pools to change your IP address frequently, ensuring your activity appears to come from multiple users.
Practice #3: Pretend to Use Different Devices
A bot’s repetitive behavior—such as using the same browser and user-agent for every request—is easy to spot. Amazon can identify patterns that don’t match typical human browsing behavior.
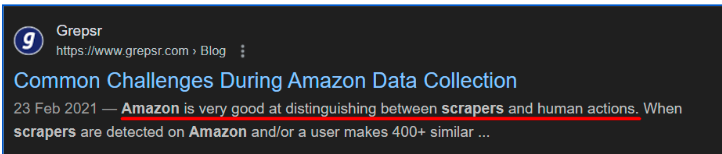
What to do? Rotate user-agent strings to make your bot appear as if it’s coming from different browsers or devices, such as mobile phones, tablets, or desktops.
This simple trick can really help reduce suspicion. So the key here:
DON’T ❌
Use the same browser fingerprint or user-agent string for all requests. This creates a clear pattern that Amazon can detect.
DO ✅
Rotate user-agent strings to simulate traffic from different devices, such as mobile phones, tablets, and desktops.
Practice #4: Don’t Overload Amazon
Overloading Amazon’s servers with frequent or simultaneous requests can trigger rate-limiting mechanisms or even get your IP blacklisted.
Here’s how Amazon’s rate-limiting mechanisms look like:

So you have to mimic human behavior by taking breaks and delays between requests to stay safe while scraping Amazon data. ALSO keep the request frequency low and avoid making loaded requests to stay under the radar.
Example:
A company’s Amazon web scraper retrieving data from hundreds of product pages in under five minutes. Amazon detects this unusual speed and blocks the scraper.
SOOOOOOO
DON’T ❌
Don’t send continuous requests without any delays. Scraping at an unnatural speed makes your activity look robotic.
DO ✅
Introduce random pauses of 3-10 seconds between requests to simulate human browsing behavior and reduce detection risks.
Practice #5: Solve Captchas with Tools
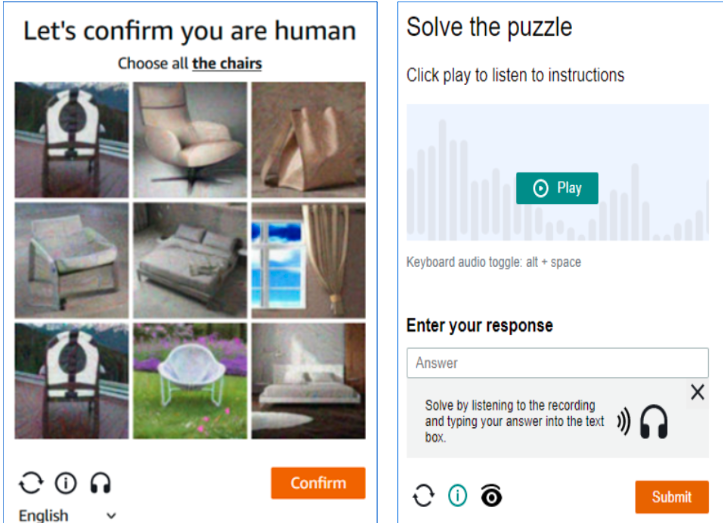
Amazon uses Captchas as a gatekeeper to ensure only real humans access their data. Encountering a Captcha can stop a scraper in its tracks, disrupting the entire workflow.
LinkedIn’s Platform Limitations for Email scraping
To tackle this like a pro, use Captcha-solving tools or services to handle these challenges automatically, ensuring your scraper continues to function smoothly.
For example:
Being a beginner scraper you might encounter frequent Captchas while extracting product data from Amazon. You’d manually solve each Captcha, wasting hours in the process.
SO DON’T ❌
Manually solve Captchas or abandon the scraping task when Captchas appear. This interrupts your workflow and reduces efficiency.
DO ✅
Integrate Captcha-solving tools like 2Captcha or Anti-Captcha into your scraper to handle challenges automatically and maintain smooth operations.
Practice #6: Stick to Publicly Available Information
Many people worry about crossing the line into unethical or illegal behavior when scraping as it may lead to legal issues or reputational damage.
Here’s a list of some publicly available data and private data:
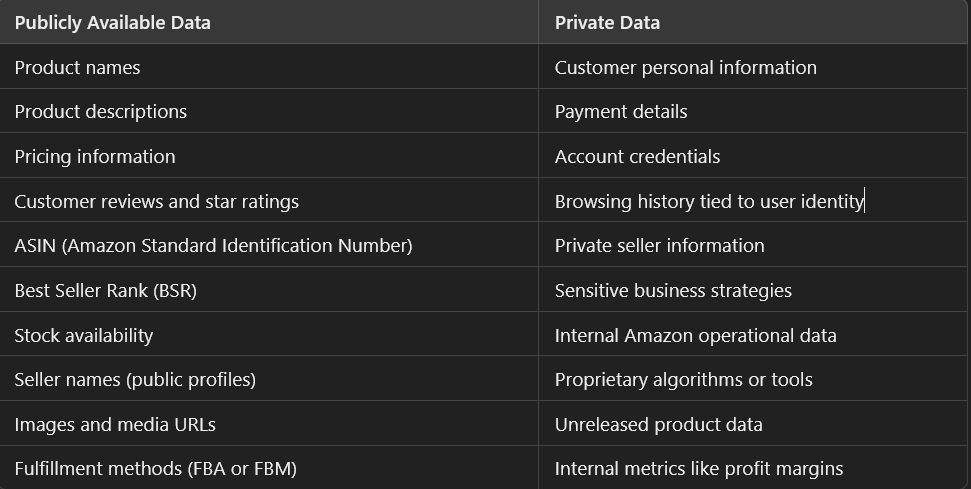
So only scrape Amazon public data and adhere to Amazon’s terms of service and local laws to avoid ethical dilemmas and legal risks while still gathering valuable information.
Practice #7: Test on Small Data First
Jumping straight into large-scale Amazon web scraping without preparation often results in broken scripts, incomplete data, and detection by Amazon’s systems.
So never despise small beginnings.
If you start small, it allows you to identify issues, refine your approach, and gradually scale operations while minimizing risks and errors.
Example:
A company running their scraper on 20,000 product pages without testing it first. The scraper may crash halfway due to an unhandled error, and the data collected is incomplete.
What to do?
DON’T ❌: Position your scraper on a large dataset immediately without testing it. This can lead to tons of wasted time and resources.
DO ✅: Test your scraper on a small batch of 100 pages first, identify and fix issues, and then scale up gradually once it’s stable.
Practice #8: Follow Ethical Practices and Laws
Unauthorized or unethical scraping can violate Amazon’s terms of service and even local or international laws.
Scraping private or sensitive data could result in lawsuits, fines, or bans. Additionally, businesses that engage in unethical scraping risk damaging their reputation if caught.
So Follow Ethical Practices and Laws:
- Scrape only publicly accessible data, such as product listings, prices, and reviews.
- Avoid collecting personal or sensitive information that is protected by data privacy laws.
- Review and adhere to Amazon’s terms of service to ensure compliance.
- Stay informed about regional data protection laws to avoid legal pitfalls.
Practice #9: Keep an Eye on Website Changes
Amazon frequently updates its website structure, causing scraping scripts to fail or collect incorrect data. This can result in incomplete or outdated datasets which is so frustrating.
Regularly monitor Amazon’s website structure and adapt your scripts to handle updates, ensuring your scraping remains accurate and reliable.
SO,
DON’T ❌
Ignore changes to Amazon’s website structure. Continuing to use outdated scripts can lead to errors or missed data.
DO ✅
Regularly monitor Amazon’s website for changes, such as updates to HTML tags or new elements. And adjust your scraper to align with these updates, ensuring accurate and reliable data extraction.
Common Mistakes to Avoid When Scraping Amazon
Here are a few common mistakes to avoid while scraping Amazon product data:
1. Sending Too Many Requests at Once
- Why It’s a Mistake: Overloading Amazon’s servers can quickly trigger rate-limiting mechanisms and result in IP bans.
- How to Avoid: Add in delays between requests to mimic human browsing behavior.
2. Using Static IPs
- Why It’s a Bad Idea: This is due to the fact that for each request from one IP, it will be pretty easy for Amazon to flag scrapers.
- How to Avoid: Rotate your proxies or a VPN so that requests would come from different IPs.
3. Not Solving Amazon’s CAPTCHA Challenges
- Why It’s a Bad Idea: Since not solving a CAPTCHA will just halt your scraper and flag you.
- How to Avoid: Use services that automatically solve CAPTCHAs.
4. Not Rotating User Agents
- Why It’s a Mistake: Sending every request from one User-Agent raises the red flag for automated activity.
- How to Avoid: Rotate User-Agents to look like different browsers and devices.
5. Scraping Too Much Data Too Fast
- Why It’s a Mistake: This overwhelms the system with so much data in a very short time, thus triggering detection and block systems of Amazon.
- How to Avoid: Take smaller chunks, and perform the scrapes with time intervals.
In Conclusion
Scraping Amazon product data can unlock a boatload of valuable insights, but it’s very essential for you to do it right.
Just by following these best practices—understanding Amazon’s protection mechanisms, and adhering to ethical guidelines—you can gather the data you need without risking bans or legal issues.
Ready to go scrape Amazon?
FAQ
Scraping publicly available data is generally legal, but you have to follow Amazon’s Terms of Service and avoid collecting private or sensitive information.
Yes, scraping Amazon without following best practices (e.g., sending too many requests or failing to rotate IPs) can result in temporary or permanent bans.
Amazon scraping helps businesses analyze competitor pricing, product performance, and market trends, driving informed business decisions.
Tools like proxy managers, CAPTCHA solvers, and using Amazon scrapers like ScrapeLead Amazon scraper can help you scrape data efficiently and securely.
Stick to publicly available data, rotate IP addresses, limit request rates, and respect regional data privacy laws.
Related Blog

11 Real-World Use Cases of Web Scraping in 2025
Explore 11 powerful examples of web scraping and see how to use data to gain insights, leads, and a market edge in 2025.

Which Review Scraper Is Best for Your E-commerce Business?
Want a simple way to start scraping reviews? Learn how to grab real customer feedback and make smarter product decisions fast.

How to Scrape Social Media Without Coding (2025 Guide)
Discover how to collect social media data effortlessly with no-code tools in this 2025 guide.