
Explore the Top 9 Challenges in Web Scraping
You’re trying to get data from websites for your business, research or project. Sounds simple right? Not-so-fast. Web scraping the process of pulling data from websites comes with its own set of web scraping challenges.
Websites change their layout overnight, CAPTCHAs are designed to drive you crazy, and scraping data is not a walk in the park. And while you’re scraping data website owners are working just as hard to figure out how to prevent website scraping. It’s a constant battle between data seekers and data protectors.
In this post, we’ll cover the biggest web scraping problems, give you practical solutions to them, and even look into the minds of website owners to see how they try to stop scrapers. Whether you’re a beginner or a pro this guide will help you navigate the wild west of web scraping with ease.
Let’s get started!
Top 9 Web Scraping Challenges
1. Website Changes: The Moving Target
One of the biggest problems with web scraping is that websites change. You write a perfect scraper today and it breaks tomorrow because the website changed its layout or code.
Why?
Websites are always changing. They might redesign their pages, reorganize their data, or switch to a new CMS. These changes can break your scraper because it relies on specific HTML tags, classes, or IDs to extract the data.
How to handle:
- Utilize libraries such as BeautifulSoup or Selenium which can better deal with changes or accommodate XPath and CSS Selectors which are more versatile.
- Use machine learning models to adapt to changes automatically.
- Use flexible code that does not depend on very specific HTML elements.
- Check your scrapers on a regular basis to ensure they’re running fine.
2. Anti-Scraping Measures: The Cat-and-Mouse Game
Many sites don’t want to be scrapped, so they use various ways to block or detect scrapers. These can range from simple CAPTCHAs to complex bot detection systems.
Anti-scraping methods:
CAPTCHAs: Are you human? Or those frustrating tests wherein you are required to recognize things within images or to enter hard-to-read text.
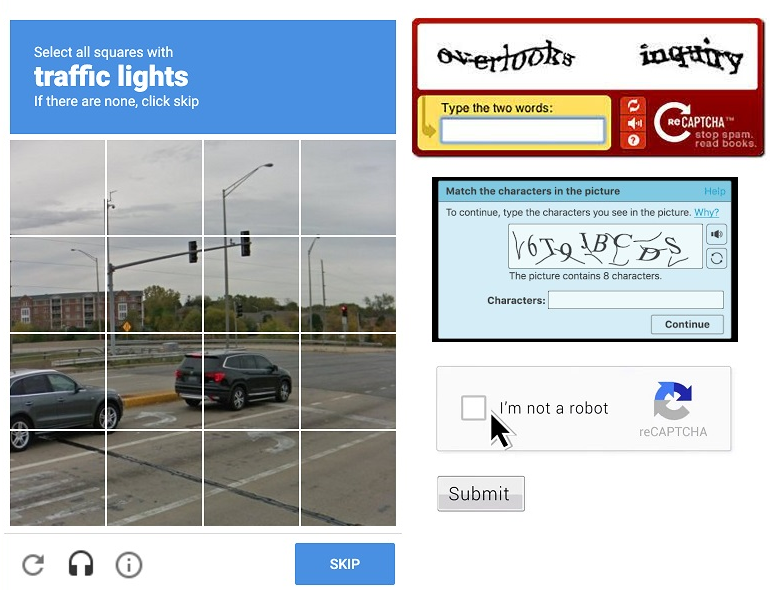
- IP Blocking: Block IP addresses that make too many requests in a short time.
- Rate Limiting: Limit requests per user or IP address.
- Honeypots: Traps in the site’s code that only bots will trigger.
How to handle:
- Use proxies or rotating IP addresses to avoid detection.
- Slow down your scraping speed to act like a human.
- Use headless browsers like Puppeteer or Selenium to bypass simple bot detection.
- For CAPTCHAs, consider using CAPTCHA-solving services (though that’s kinda cheating).
3. Dynamic Content: The JavaScript Problem
Modern websites load content via JavaScript. The data you see on the page isn’t always in the initial HTML source code—it’s loaded later by JavaScript.
Why is this a problem?
Traditional scrapers like BeautifulSoup or Scrapy can only read static HTML. If the data is loaded dynamically, they won’t be able to get it.
How to handle:
- Use tools like Selenium, Puppeteer, or Playwright that can render JavaScript and interact with dynamic content.
- Analyze the website’s API (if available) to fetch data directly instead of scraping the front end.
- Be prepared to slow down your scraping as rendering JavaScript takes more time and resources.
4. Legal and Ethical Concerns: The Balancing Act
Web scraping isn’t just a technical task—it’s a legal and ethical minefield. Some websites explicitly forbid scraping in their terms of service and scraping without permission will get you in trouble.
Legal rules:
- Copyright: Scraping copyrighted content without permission will get you sued.
- Terms of Service: Violating a website’s terms of service will get you in trouble.

- Data Privacy: Scraping personal data (e.g. names, emails) will violate privacy laws like GDPR or CCPA.

How to handle:
- Don’t scrape sensitive or personal data.
- Check the website’s robots.txt file. It informs you about what part of the site is acceptable to scrape and what is not.
- When scraping for commercial use, mail the web owners and request their permission. A little can go a long way!
5. Data Quality: Garbage In, Garbage Out
Even if you scrape the data correctly, there’s no guarantee it will be clean and usable. Sites have inconsistent formatting, missing fields, or errors that can destroy your dataset.
Common data quality issues:
- Inconsistent formats (e.g. dates in “MM/DD/YYYY” vs “DD-MM-YYYY”).
- Missing or incomplete data.
- Duplicates.
- Errors or typos in the original data.
How to handle:
- Clean and preprocess your scraped data. Use Python libraries like Pandas to remove duplicates, handle missing values, and correct errors.
- Implement validation checks in your scraper to flag or fix errors during extraction.
- Review a sample of the data manually.
6. Scalability Problems: When Bigger Isn’t Better
Scraping a few pages is easy, but what if you need to scrape thousands or millions of pages? Suddenly you’re dealing with server load, storage, and speed.
Common scalability issues:
- Server Overload: Making too many requests too fast can crash a website or get your IP blocked.
- Storage: Large datasets require a lot of storage space and efficient database management.
- Speed: Scraping at scale can be slow especially if you’re trying to avoid detection.
How to handle:
- Use distributed scraping frameworks like Scrapy with Redis or Apache Kafka.
- Store data in efficient databases like PostgreSQL or MongoDB.
- Use cloud services like AWS or Google Cloud for storage and computing power.
7. Pagination and Infinite Scroll: The Never-Ending Story
Some websites have content spread across multiple pages (pagination) or load more data as you scroll (infinite scroll).
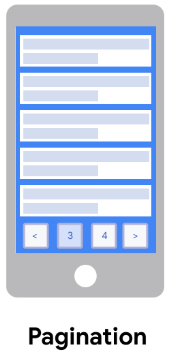
- Pagination: You have to loop through page numbers or “Next” buttons which can be inconsistent or hidden.
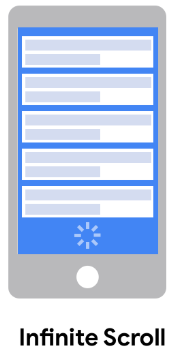
- Infinite Scroll: Content loads dynamically and often without an end, so you don’t know when you’ve scraped everything.
How to handle:
- For pagination, look for patterns in the URL (e.g. page=2) or use Selenium to click “Next” buttons.
- For infinite scroll, simulate scrolling with tools like Puppeteer and track when no new content loads.
8. Session Management and Logins: Breaking Through the Wall
Some data is behind login walls (e.g. social media, subscription sites). And if you want to scrape thate datathen you requires handling authentication
Why it’s hard:
- Logins involve cookies, sessions, and tokens that expire.
- Websites can detect repeated login attempts and block your IP.
How to handle:
- Use requests.Session() in Python to persist cookies.
- Rotate user agents and IPs to avoid detection.
- Don’t scrape behind logins unless you have explicit permission.
9. Geo-Blocking and Regional Restrictions: Location, Location, Location
Some websites show different content based on a user’s location. E.g. e-commerce sites show region-specific prices.
Why it’s hard:
- Your scraper might miss data if it’s not accessing the website from the “right” location.
- Proxies can be slow or unreliable.
How to handle:
- Use geo-targeted proxies to mimic locations.
- Test with VPNs to make sure you’re scraping the correct version of the site.
Wrap Up
Web scraping is a rollercoaster – exciting but full of twists and turns. Websites change, CAPTCHAs block you, and dynamic content is tricky. But with the right tools and a bit of patience, you can overcome these hurdles.
In this post we’ve covered the biggest obstacles – website changes, scaling your scraper, and staying on the right side of the law – and give you practical tips to scrape smarter.
If you want to try a free tool for scraping, ScrapeLead is a free and simple tool that makes web scraping for everyone, whether you’re a beginner or a pro.
So, take a deep breath, keep trying, and remember: that every challenge is just a step closer to mastering web scraping.
Happy scraping!
Related Blog

11 Real-World Use Cases of Web Scraping in 2025
Explore 11 powerful examples of web scraping and see how to use data to gain insights, leads, and a market edge in 2025.

Which Review Scraper Is Best for Your E-commerce Business?
Want a simple way to start scraping reviews? Learn how to grab real customer feedback and make smarter product decisions fast.

How to Scrape Social Media Without Coding (2025 Guide)
Discover how to collect social media data effortlessly with no-code tools in this 2025 guide.