Contents

How to Scrape Reddit with Python: Full Step-by-Step Guide
You’re working on a task and need useful information from Reddit – a hub of discussions, opinions, and trends.
Be it working on the analysis of best posts on Reddit, searching for feedback from users, or researching a specific niche, it is obvious that manual gathering is not an option.
And here’s where automation is needed. Whether it’s through PRAW in Python to automate API requests, or simply submitting commands for scraping HTML files, there are different options for scraping Reddit.
In the case of people who are not knowledgeable about coding, there are tools like ScrapeLead’s Reddit Scraper that do not require knowledge of coding to scrape Reddit pages.
This is a guide in which we will cover different methods for scraping Reddit data including writing Python scripts and employing tools such as ScrapeLead to make the process easier.
So let’s begin!
1) Using PRAW
PRAW Stands for – Python Reddit API Wrapper
Reddit PRAW is a Python library that is specially designed to simplify interaction with Reddit’s API.
You can scrape Reddit data like posts, comments, and user information with PRAW.
How does PRAW work?
Connected with official Reddit API: For reliable safety- guarantee scraping process.
Extracts Data: Extract subreddit posts, comments, and user profiles.
Customization: Filter data concerning keywords, dates, etc.
How to Scrape Reddit with PRAW?
If you want to use PRAW, you have to write Reddit codes, which are Python codes.
Step 1: You have to install the PRAW package using the following command;
pip install praw
Step 2: To use PRAW, you will need to have API credentials from Reddit.
To begin using Reddit’s API create a Reddit app :
1. Search Reddit’s app developer page.
2. Click on “Create App” or “Create another App” and enter some details about your app.
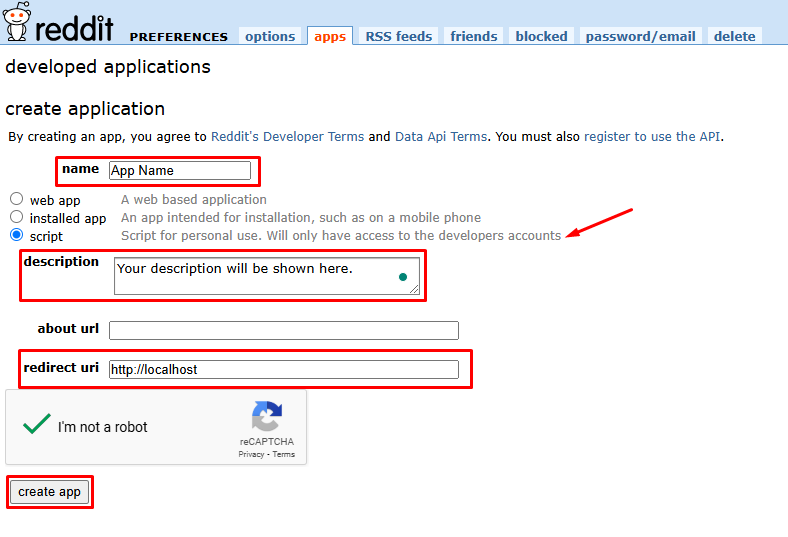
3. Select “script” as the app type (For personal use or scraping)
4. Fill up the name, description, and redirect URL (use http://localhost or any placeholder URI for testing.)
5. Click on “Create App” to get client_id, client_secret, and user_agent.
To know what is your client_id and client_secret,
Click on “edit”.
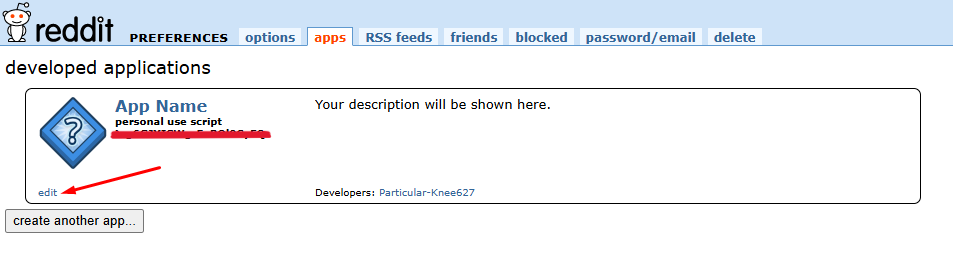
And you can see client_id and client_secret.
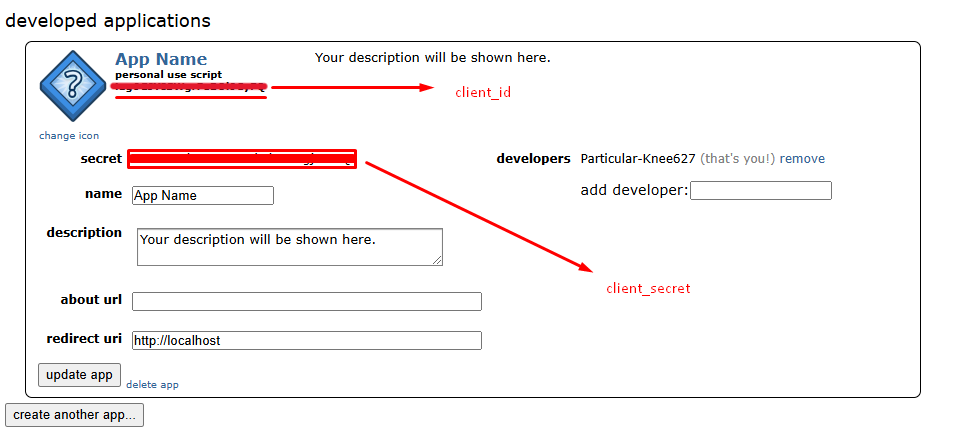
Important Reminder
- client_id is public and identifies your app.
- client_secret should be kept secret. Do not upload it to public repositories.
- Always append your user_agent to abide by Reddit’s API policies.
- A user_agent is just a custom string that marks your application. Create it on your own.
- Format: Appname/Version by Yourusername.
- Example: RedditScraper/1.0 by MyRedditUsername
Let’s Start
For example:
Below is the complete Reddit Python code for authenticating with Reddit using PRAW and retrieving the top Reddit posts (5) from the r/technology subreddit:
import praw
# Reddit API credentials
client_id = "YourClientID" # Replace with your actual client ID
client_secret = "YourClientSecret" # Replace with your actual client secret
user_agent = "YourAppName/1.0 by YourUsername" # Replace with your user agent
# Initialize the PRAW instance
reddit = praw.Reddit(
client_id=client_id,
client_secret=client_secret,
user_agent=user_agent
)
# Test connection
try:
print(f"Authenticated as: {reddit.user.me()}")
except Exception as e:
print(f"Authentication failed: {e}")
# Choose a popular subreddit
subreddit_name = "technology" # Example: r/technology
subreddit = reddit.subreddit(subreddit_name)
# Fetch the top 5 hottest posts
print(f"\nFetching the hottest posts from r/{subreddit_name}...\n")
for post in subreddit.hot(limit=5): # Adjust the limit as needed
print(f"Title: {post.title}")
print(f"Author: {post.author}")
print(f"Upvotes: {post.ups}")
print(f"URL: {post.url}")
print("-" * 50)
# Example: Fetch comments from the first post
print("\nFetching comments from the first hot post...\n")
first_post = next(subreddit.hot(limit=1)) # Get the first post
first_post.comments.replace_more(limit=0) # Ensure all comments are loaded
for comment in first_post.comments.list()[:5]: # Limit to 5 comments
print(f"Comment by {comment.author}: {comment.body}")
print("-" * 50)
# Fetch user information (replace 'username' with a Reddit username)
print("\nFetching user data...\n")
username = "spez" # Example username
redditor = reddit.redditor(username)
print(f"Username: {redditor.name}")
print(f"Karma: {redditor.link_karma + redditor.comment_karma}")
print(f"Account Created: {redditor.created_utc}")
print(f"Is Moderator: {redditor.is_mod}")
Let’s break it down.
1. Importing the PRAW Library
This imports the library PRAW (Python Reddit API Wrapper) which makes working in Python with the Reddit API smoother.
import praw
2. Set credentials for the Reddit API
First, we have to get access to the data on Reddit.
This is made possible through something known as the Reddit API. To connect, you’ll need three things:
# Reddit API credentials
client_id = "YourClientID" # Replace with your actual client ID
client_secret = "YourClientSecret" # Replace with your actual client secret
user_agent = "YourAppName/1.0 by YourUsername" # Replace with your user agent
3. Connecting to Reddit
With our credentials, we are ready to use PRAW to connect to Reddit.
PRAW is merely a tool that allows us to converse easily with Reddit without going into the intricate details of doing it on our own.
# Initialize the PRAW instance
reddit = praw.Reddit(
client_id=client_id,
client_secret=client_secret,
user_agent=user_agent
)
This line creates a connection to Reddit using the credentials given.
4. Checking if we’re Connected or Not.
We are trying to verify our connection.
So, let’s say we have our username, and we would like to verify that we are logged in.
# Test connection
try:
print(f"Authenticated as: {reddit.user.me()}")
except Exception as e:
print(f"Authentication failed: {e}")
If it succeeds, it will be like this:
But if it does not succeed, then there will be an error.
How to resolve an error in cases when you get one?
- Make sure you verify your client_id and client_secret. (You could have a typo.)
- Invalid user_agent.
- Your IP could be blacklisted if you are using a VPN. Disable the VPN.
5. Choosing a Subreddit
We now have to choose which subreddit we want to browse.
Subreddits are similar to categories on Reddit where people share content.
In this case, let’s choose r/technology.
# Choose a popular subreddit
subreddit_name = "technology" # Example: r/technology
subreddit = reddit.subreddit(subreddit_name)
We simply use reddit.subreddit(“technology”) to get a “subreddit” object that allows us to retrieve posts and other information from there.
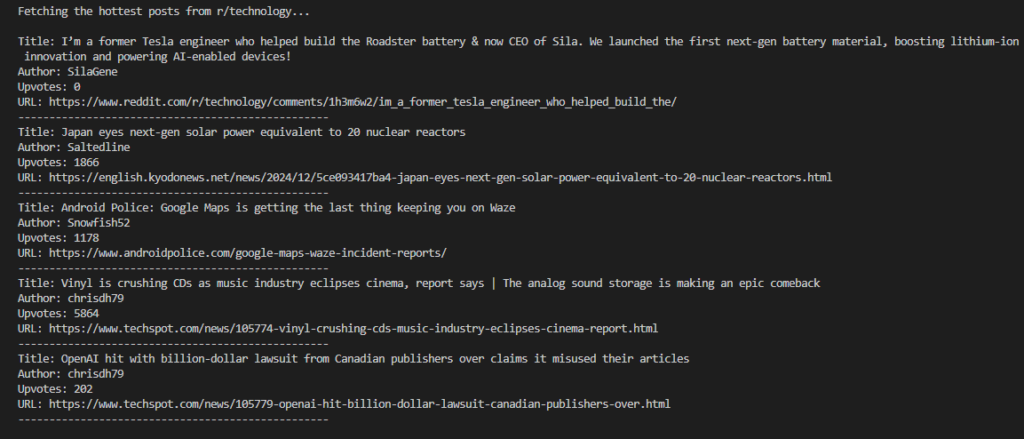
6. Getting the Top 5 Posts
Now, we will get the hottest posts in that subreddit with posts currently being hot.
# Fetch the top 5 hottest posts
print(f"\nFetching the hottest posts from r/{subreddit_name}...\n")
for post in subreddit.hot(limit=5): # Adjust the limit as needed
print(f"Title: {post.title}")
print(f"Author: {post.author}")
print(f"Upvotes: {post.ups}")
print(f"URL: {post.url}")
print("-" * 50)
Print out the title, author, number of upvotes, and URL of each post.
You can customize the limit based on your comfort level.
Output:
7. Retrieving Comments of the First Post
Let’s dive deeper into the first post we retrieved.
We would like to see the comments people left on it.
We will load all comments and display just a few.
# Example: Fetch comments from the first post
print("\nFetching comments from the first hot post...\n")
first_post = next(subreddit.hot(limit=1)) # Get the first post
first_post.comments.replace_more(limit=0) # Ensure all comments are loaded
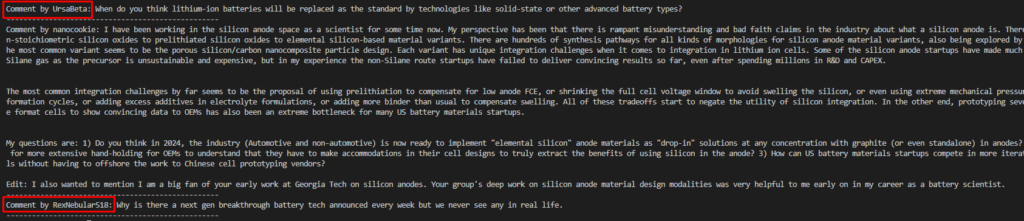
for comment in first_post.comments.list()[:5]: # Limit to 5 comments
print(f"Comment by {comment.author}: {comment.body}")
print("-" * 50)
replace_more(limit=0) ensures that we load all comments, not just the “more comments” placeholders.
first_post.comments.list()[:5] fetches the first 5 comments and prints them out.
Output:
8. User Information
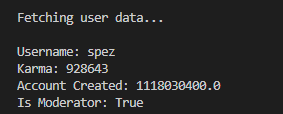
The following code fetches information about a Reddit user, including their username, total karma, account creation date, and moderator status.
# Fetch user information (replace 'username' with a Reddit username)
print("\nFetching user data...\n")
username = "spez" # Example username
redditor = reddit.redditor(username)
print(f"Username: {redditor.name}")
print(f"Karma: {redditor.link_karma + redditor.comment_karma}")
print(f"Account Created: {redditor.created_utc}")
print(f"Is Moderator: {redditor.is_mod}")
You can replace ‘spez’ with any other username to view their stats.
Output
Pro tip: Use loops and Limits.
So this is the way you can do Reddit scrapping using Reddit API Python.
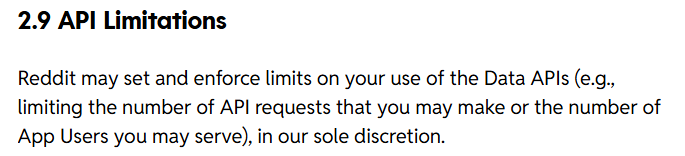
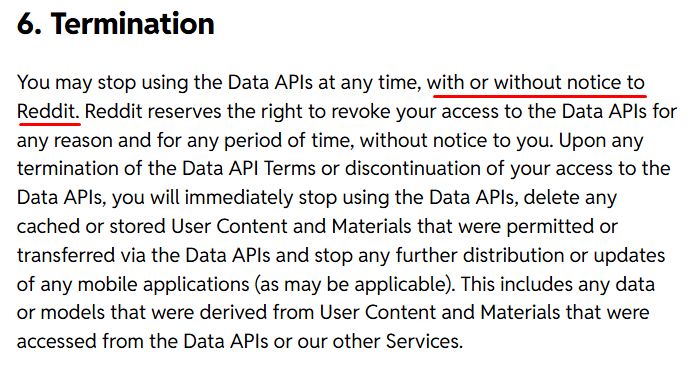
But wait, if you are using Python Reddit API then there are some limitations too.
Limitation of Reddit API:


Hold your horses! The Privacy Policy has more secrets than a spy novel.
Let’s talk about money!!
How much does Reddit API cost for web scraping Reddit?
Well, you can use the Reddit API for free in most cases, like personal projects, research, and moderate commercial stuff.
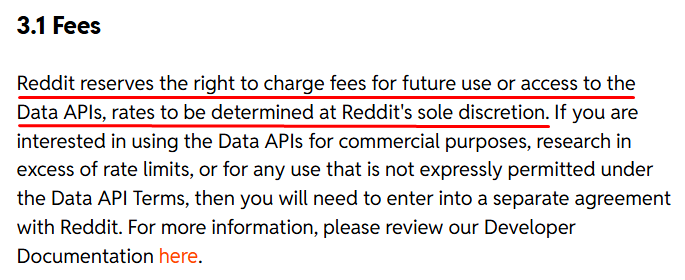
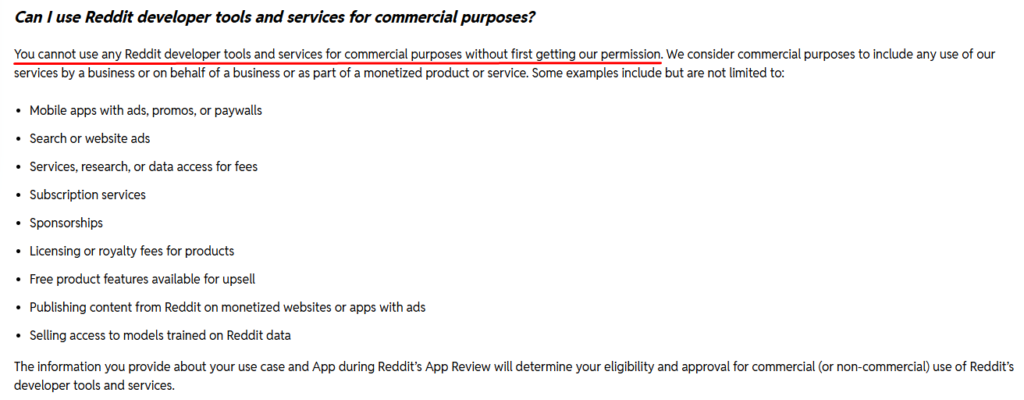
You need Reddit’s permission if you want to use it commercially.
Hey, did you hear that Reddit now has paid API tiers?
They’re targeting third-party apps that make money off Reddit’s data.
In July 2023, Reddit decided to spice things up with a new monetization strategy for its API.

Reddit API costs: revealed successfully!
Well, there is another method also for Reddit web scraping.
2) Using Request Library
So,
How to scrape Reddit data using Request??
Requirements for Reddit scraping:
- Of course Python
- Request Library
- BeautifulSoup Library (Optional)
- Peace full Environment
- And a cup of Espresso
First, check out the whole code:
import requests
import json
from datetime import datetime
# Base Reddit URL for API requests
base_url = 'https://www.reddit.com'
input_name = 'r/Futurology' # Change this to the subreddit or user you want to scrape
headers = {'User-Agent': 'Mozilla/5.0'}
# Function to check if the input is a subreddit or not
def is_subreddit(input_name):
return input_name.startswith('r/')
# Converts epoch timestamp to a readable date format
def convert_epoch_to_date(epoch_time):
return datetime.fromtimestamp(epoch_time).strftime('%Y-%m-%d %H:%M:%S')
# Determines the correct API endpoint based on input (subreddit or user)
if is_subreddit(input_name):
endpoint = f'/{input_name}/about.json' # Subreddit endpoint
else:
endpoint = f'/{input_name.replace("u/", "user/")}/about.json' # User endpoint
# Fetch data from the Reddit API
def fetch_data(endpoint):
url = base_url + endpoint
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise error if the request fails
return response.json()
# Fetch data for the given subreddit or user
profile_info = fetch_data(endpoint)
# Initialize a dictionary to store data
temp_dict = {}
if is_subreddit(input_name):
# Customize the fields you want to extract for subreddits
temp_dict['display_name'] = profile_info['data'].get('display_name', '')
temp_dict['header_img'] = profile_info['data'].get('header_img', '')
temp_dict['title'] = profile_info['data'].get('title', '')
temp_dict['active_user_count'] = profile_info['data'].get('active_user_count', '')
temp_dict['subscribers'] = profile_info['data'].get('subscribers', '')
temp_dict['public_description'] = profile_info['data'].get('public_description', '')
temp_dict['submit_text'] = profile_info['data'].get('submit_text', '')
temp_dict['created'] = convert_epoch_to_date(profile_info['data'].get('created', ''))
temp_dict['subreddit_type'] = profile_info['data'].get('subreddit_type', '')
temp_dict['description'] = profile_info['data'].get('description', '')
else:
# Customize the fields you want to extract for user profiles
temp_dict['banner_img'] = profile_info['data']['subreddit'].get('banner_img', '')
temp_dict['display_name'] = profile_info['data']['subreddit'].get('display_name', '')
temp_dict['title'] = profile_info['data']['subreddit'].get('title', '')
temp_dict['icon_img'] = profile_info['data']['subreddit'].get('icon_img', '')
temp_dict['display_name_prefixed'] = profile_info['data']['subreddit'].get('display_name_prefixed', '')
temp_dict['url'] = profile_info['data']['subreddit'].get('url', '')
temp_dict['public_description'] = profile_info['data']['subreddit'].get('public_description', '')
temp_dict['awardee_karma'] = profile_info['data'].get('awardee_karma', '')
temp_dict['awarder_karma'] = profile_info['data'].get('awarder_karma', '')
temp_dict['link_karma'] = profile_info['data'].get('link_karma', '')
temp_dict['total_karma'] = profile_info['data'].get('total_karma', '')
temp_dict['name'] = profile_info['data'].get('name', '')
temp_dict['created'] = convert_epoch_to_date(profile_info['data'].get('created_utc', ''))
temp_dict['snoovatar_img'] = profile_info['data'].get('snoovatar_img', '')
temp_dict['comment_karma'] = profile_info['data'].get('comment_karma', '')
# Print the extracted data in a formatted JSON structure
print(json.dumps(temp_dict, indent=4))
Time to break down:
1: Importing Required Libraries
import requests
import json
from datetime import datetime
requests: This is used for making HTTP requests to the Reddit API.
json: This is used for handling and printing data in JSON format.
datetime: This is used for converting Reddit’s timestamp into a human-readable format.
2: Setting Up Basic Variables
Set the base URL for accessing the Reddit API and assign the subreddit or the user, whom we intend to scrape for data:
# Base Reddit URL for API requests
base_url = 'https://www.reddit.com'
input_name = 'r/Futurology' # Change this to the subreddit or user you want to scrape
headers = {'User-Agent': 'Mozilla/5.0'}
base_url = ‘https://www.reddit.com’.
input_name: Here’s the input of the subreddit or the username to be scraped, eg, ‘r/Futurology’ for a subreddit, or ‘u/username’ for a user.
headers: Reddit requires a “User-Agent” header to not be blocked on requests.
It is set to emulate a browser request.
3: Check if Input is a Subreddit
We define a function to check whether the input_name is a subreddit or a user:
# Function to check if the input is a subreddit or not
def is_subreddit(input_name):
return input_name.startswith('r/')
is_subreddit(input_name): This function checks if input_name starts with ‘r/’. If it does, then it’s a subreddit.
4: Convert Epoch Time to Human-Readable Date
For the dates, Reddit uses the UNIX timestamp (epoch time), which is the number of seconds since January 1, 1970.
We’ll need a function to convert it into a readable date format:
# Converts epoch timestamp to a readable date format
def convert_epoch_to_date(epoch_time):
return datetime.fromtimestamp(epoch_time).strftime('%Y-%m-%d %H:%M:%S')
convert_epoch_to_date(epoch_time): It will take epoch time and return the conversion to a human-readable format, that is, YYYY-MM-DD HH:MM:SS.
5: Creating the API Endpoint
Depending on if you are scraping a subreddit or a user, you’ll have a different endpoint:
# Determines the correct API endpoint based on input (subreddit or user)
if is_subreddit(input_name):
endpoint = f'/{input_name}/about.json' # Subreddit endpoint
else:
endpoint = f'/{input_name.replace("u/", "user/")}/about.json' # User endpoint
If it is a subreddit, you will use /{subreddit_name}/about.json as an endpoint;
If it is a user, you will use /{username}/about.json as an endpoint;
Using an if-else condition we get to which endpoint.
6: Getting the data from Reddit API
The function fetch_data(endpoint) sends a GET request to the Reddit API with the endpoint to retrieve information for the subreddit or the user:
# Fetch data from the Reddit API
def fetch_data(endpoint):
url = base_url + endpoint
response = requests.get(url, headers=headers)
response.raise_for_status() # Raise error if the request fails
return response.json()
requests.get(url, headers=headers): This sends a GET request to the Reddit API.
response.raise_for_status(): This will raise an exception if there is any error with the request.
response.json(): This converts the API response into a JSON object that can be easily used.
7: Fetch Data for SubReddit or User
After preparing the API endpoint, we fetch the data for the given subreddit or user:
# Fetch data for the given subreddit or user
profile_info = fetch_data(endpoint)
profile_info = fetch_data(endpoint): It fetches the data of the subreddit or user according to the endpoint we prepared earlier.
8: Extract Data and Store in a Dictionary
We have a dictionary temp_dict in which we will store the fetched data.
According to the input, whether it is a subreddit or a user, we fetch different fields:
# Initialize a dictionary to store data
temp_dict = {}
if is_subreddit(input_name):
# Customize the fields you want to extract for subreddits
temp_dict['display_name'] = profile_info['data'].get('display_name', '')
temp_dict['header_img'] = profile_info['data'].get('header_img', '')
temp_dict['title'] = profile_info['data'].get('title', '')
temp_dict['active_user_count'] = profile_info['data'].get('active_user_count', '')
temp_dict['subscribers'] = profile_info['data'].get('subscribers', '')
temp_dict['public_description'] = profile_info['data'].get('public_description', '')
temp_dict['submit_text'] = profile_info['data'].get('submit_text', '')
temp_dict['created'] = convert_epoch_to_date(profile_info['data'].get('created', ''))
temp_dict['subreddit_type'] = profile_info['data'].get('subreddit_type', '')
temp_dict['description'] = profile_info['data'].get('description', '')
else:
# Customize the fields you want to extract for user profiles
temp_dict['banner_img'] = profile_info['data']['subreddit'].get('banner_img', '')
temp_dict['display_name'] = profile_info['data']['subreddit'].get('display_name', '')
temp_dict['title'] = profile_info['data']['subreddit'].get('title', '')
temp_dict['icon_img'] = profile_info['data']['subreddit'].get('icon_img', '')
temp_dict['display_name_prefixed'] = profile_info['data']['subreddit'].get('display_name_prefixed', '')
temp_dict['url'] = profile_info['data']['subreddit'].get('url', '')
temp_dict['public_description'] = profile_info['data']['subreddit'].get('public_description', '')
temp_dict['awardee_karma'] = profile_info['data'].get('awardee_karma', '')
temp_dict['awarder_karma'] = profile_info['data'].get('awarder_karma', '')
temp_dict['link_karma'] = profile_info['data'].get('link_karma', '')
temp_dict['total_karma'] = profile_info['data'].get('total_karma', '')
temp_dict['name'] = profile_info['data'].get('name', '')
temp_dict['created'] = convert_epoch_to_date(profile_info['data'].get('created_utc', ''))
temp_dict['snoovatar_img'] = profile_info['data'].get('snoovatar_img', '')
temp_dict['comment_karma'] = profile_info['data'].get('comment_karma', '')
For SubReddit: It fetches details like the name of the display on the subreddit, header image, description, subscribers, etc.
For Users: It fetches details like karma points, profile pictures, banner images, etc.
If you want to extract data from SubReddit,

Just change the name.
If you want to extract data from User,

Replace “r” with “u” and change username.
That’s it, my lord!
9: Print Extracted Data
Lastly, it prints the data in an indented JSON format:
# Print the extracted data in a formatted JSON structure
print(json.dumps(temp_dict, indent=4))
json.dumps(temp_dict, indent=4): It translates a dictionary into a more readable JSON string with indentation.
10: Run the Script
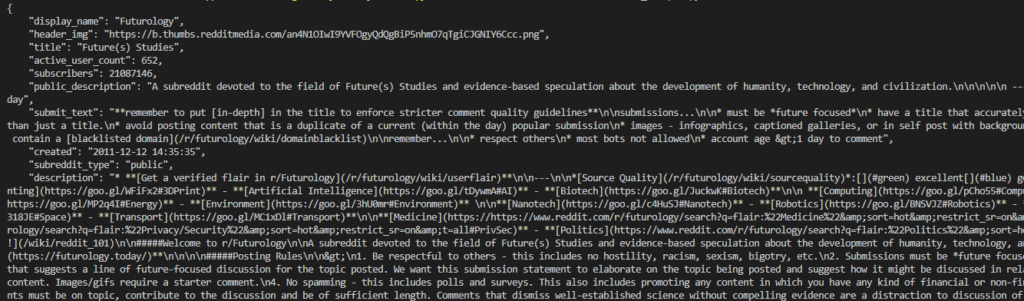
For SubReddit:
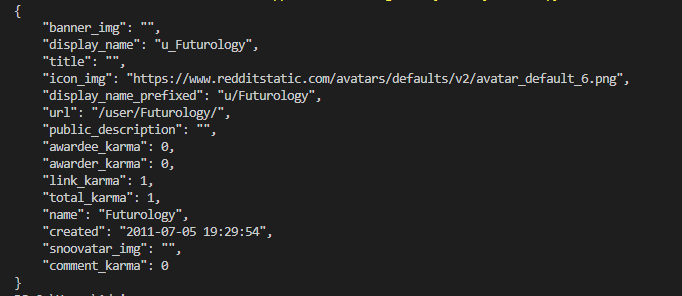
For User:
Why work hard when you can work smart and take a nap?
Use Our Reddit Web Scraper: The secret weapon for data extraction, even if you’re allergic to code.
Let me show you how easy to use our Reddit Scraper.
Let’s start with posts.
Login to ScrapeLead
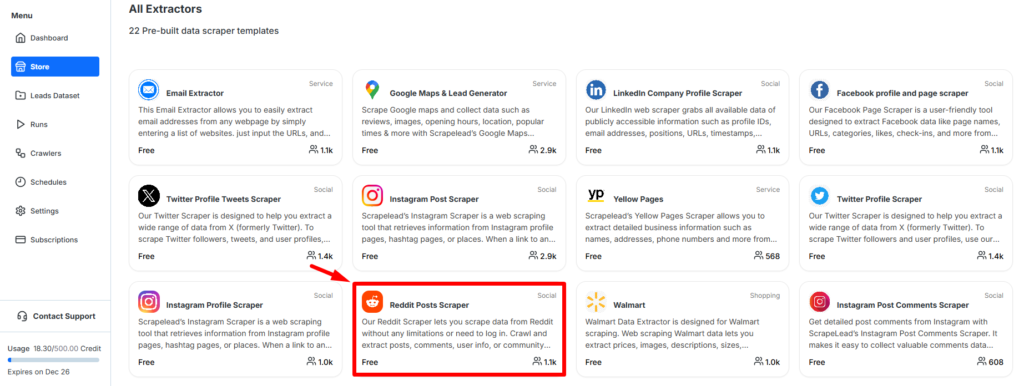
You will be redirected to our store, where you can find the Reddit Post Scraper.
Enter Reddit URL.
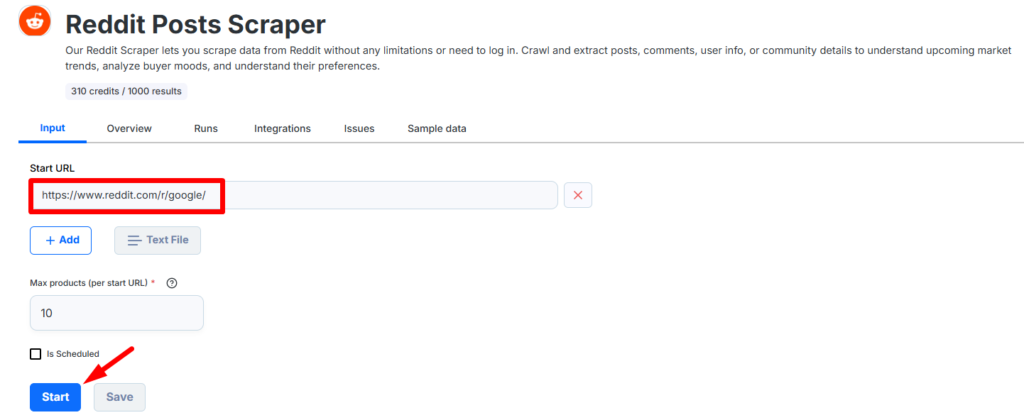
Click on Start
Your data is ready sir!
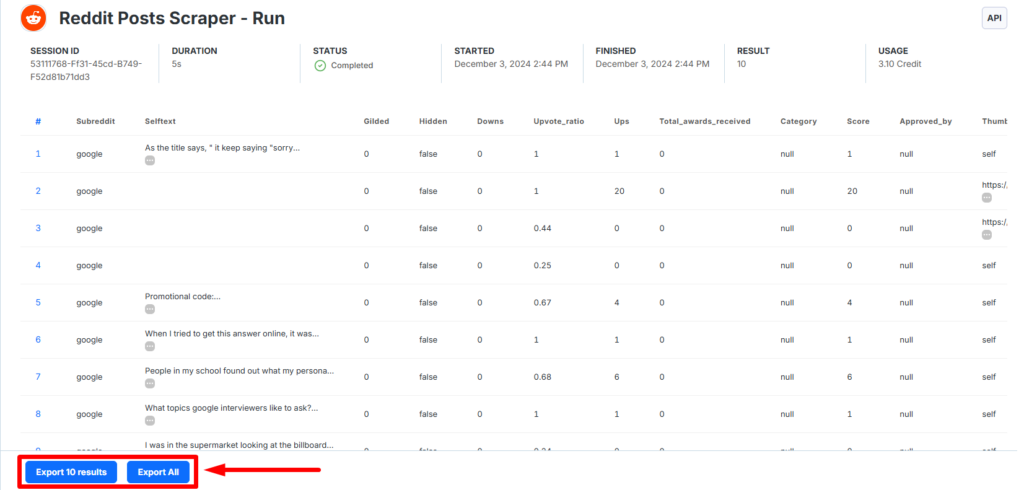
You can download Reddit data into multiple formats too.
You can extract all data from;
- Post
- Comments
- SubReddit
- User
- Media
For a detailed guide, check out:
With our tool, you can scrape Reddit page completely FREEEEEEEE!
(Without Coding)
What else do you need?
Final Words;
Depending upon the requirements and capabilities, scraping Reddit can be easily done using the PRAW or Requests Python libraries.
While using PRAW, the process of structured API-compliant scraping is supported, while with Requests, lightweight scraping is allowed.
However, in terms of convenience and scalability, professional tools like Reddit Scraper by ScrapeLead would always be the best option since it does away with all technical hitches and helps to make the process of collecting proper useful data effectively.
No matter which method is chosen, every single time, the Reddit API policies and privacy policy should be respected.
FAQ
For controlled and API-compliant scraping, PRAW is a great option. But for the rest who would rather us a no-code solution, then ScrapeLead’s Reddit Scraper is a great recommendation.
Yes, API credentials are necessary for PRAW. On the other hand, ScrapeLead’s Reddit Scraper doesn’t require any technical configuration, which is great for non-programmers.
Yes, the Requests library allows direct communication with Reddit’s JSON endpoints. However, to achieve thorough scraping, use ScrapeLead’s Reddit Scraper.
Yes, there are limits on Time and Usage Restrictions on the use of Reddit API. However, consider working with these, or ScrapeLead’s Reddit Scraper, which helps eliminate these restrictions.
If done in compliance with Reddit’s Terms of Service and API usage Guidelines, Scraping is legal. In addition, ScrapeLead’s Reddit Scraper also observes these parameters.
For most personal and research purposes, it’s free. However, any commercial use would probably incur a fee. For such cases, Tools like ScrapeLead’s Reddit Scraper are beautiful substitutes.
Start scraping instantly
Sign up now, and get free 500 credits everymonth.
No credit card required!
Related Blog

The Ultimate Guide to Amazon Reviews Scraping
Learn how to use Amazon reviews scraping to tap into genuine customer sentiment and drive business growth.

How to Scrape Glassdoor in 4 Steps
Discover how to scrape Glassdoor for valuable insights on job listings, salaries, and company reviews using ScrapeLead. It’s quick, easy, and free!

Top 5 Apify Scrapers 2025
Explore the top Apify scrapers and alternatives. Learn how Apify can automate web scraping and help you gather valuable data effortlessly.